KubernetesのCronjobを手動実行する方法
出来ないことはないだろうと思って調べてみたら方法はあった。 環境変数とか一部設定を変えてすぐ動作確認したいときに便利です。
kubectl create job <job-name> --from=cronjob/<cronjob-name>
関連Issueはこれ。
GKE環境でPCI-DSS準拠のシステムを構築した事例
GCP, GKEを使ってPCI-DSS準拠のシステムを作った事例。この動画を見て気になったところをまとめてみました。仮想通貨販売所の話は興味なかったので省略 www.youtube.com
動画メモ
PCI-DSS準拠の方針
課題
リソース不足
解決策
- PCI-DSSの対象とするスコープを減らす。個人情報、カード情報。
- GCP Project、VPCを別にする
- ログイン可能なユーザーを限定する
- 専用のG SuiteドメインからOneLoginを利用してログイン
- One Loginはパスワード要件を満たすため
アーキテクチャの全体像
クレジットカード情報、個人情報はGCPプロジェクトのみで扱うようになっている。他の情報は全て別システム。
HTTPSアクセスはFastly経由。Triple DES, TLS1.1を無効化したかったため。
FastlyのLogging endpointsを BigQuery, TCP to Kuberntes Clusterに指定している。
Fastly- Fluentd Cluster
Deployment Containers
fastlyのログを整形してStackDriverに送信している
CronJobs:
BigQueryに格納されたFastlyのログからアクセス数が異常なIPをブロックする(またはその逆)のgolangプロセス
Payment Proxy Cluster
Deployment Containers
payment-proxy: 本体。 golang
digest: Argon2 hash計算用サービス in ruby Sinatra
cloudsql-proxy: そのまま
nginx: ReverseProxy
ossec: 侵入検知プロセス(IDS) Nginxのログ監視・結果を出力
Virus Scan Cluster
Deployment Containers clamav: 他clusterにいる各containerは立ち上げ時にclamscan
Vulnerability Scan Cronjob
苦労した点良かった点
- 事例が見つからない。オンプレ前提の項目が多くどう満たせばよいかわからなかった。→頑張って事例作った
- ファイル変更検知をbastionからdocker diffすることで行える
- 本番のStackdriver Debugger使える
- SSHも自動的に二段階認証になる
- スケーラビリティもついてくる
おまけ
外部のコンサルタントを交えて行われるPCI-DSS対応のための審査をタスクとルールブックはGithub Issueで管理
感想
PCI-DSS監査対象になるシステムを最小にして、専用のGCPプロジェクト・ネットワーク、GSuiteアカウントで運用しているということでした。これ自体はまぁそうなるよなーという感じ。
cloudsql-proxy使っているということは、CloudSQLのエンドポイントはグローバルに開いていてサービスアカウントでの認証になっているはずで監査で何か言われないのかちょっと気になった。去年の発表だし、いまはプライベートIPモード使っているのかな。
ウイルススキャン、侵入検知、ファイル変更検知はオンプレやIaaSベースではよく聞くけど、コンテナベースのアーキテクチャでどうやるのかあまりイメージついてなかったので勉強になりました。特にファイル変更検知をdocker diffで簡単にできるのは気づかなかった。
監査をGithub Issueで管理するように進めてくれるのは、担当者レベルでがんばってもなかなか難しそう。会社からのバックアップがあったのだと思うので、よい文化だなーと思いました。
今までこういうメモは社内wikiに雑にまとめていたのですが、転職回数増えてくると社内wikiに書いてもいつか見れなくなってしまうしなー、と思うようになってきたので、自分のブログに載せていくことにしました。
StackDriver Monitoringにカスタムメトリクスを送信する
ここに書いてあることが全てなのですが、僕の理解力が低いのか送信するまでに色々手間取ったので備忘のため残しておきます。 cloud.google.com
Rubyのサンプルコードで説明していきます。 Ruby用のSDKをインストールして、スクリプトではSDKをrequireしてあるのが前提です。
gem install google-cloud-monitoring
require "google/cloud/monitoring"
メトリクスの作成
カスタムメトリクスを送信するためには、まずメトリクスの定義をStackDriverに送信する必要があります。 事前定義なしでいきなり送りつけることも可能ですが、その場合はStackDriver側で色々なデフォルト値が利用されます。メトリクスの定義は後から変更できないものが多いようなので、基本的には事前に定義しておいた方がよさそうです。
metric_client = Google::Cloud::Monitoring::Metric.new formatted_name = Google::Cloud::Monitoring::V3::MetricServiceClient.project_path([project_id]) label1 = Google::Api::LabelDescriptor.new( key: "label_test", description: "カスタムメトリクスへのラベル付与テスト", value_type: Google::Api::LabelDescriptor::ValueType::STRING ) md = Google::Api::MetricDescriptor.new( name: "my_first_custom_metric", type: "custom.googleapis.com/custom_metrics_test/test_metric", description: "カスタムメトリクスの説明テスト", display_name: "はじめてのカスタムメトリクス", metric_kind: Google::Api::MetricDescriptor::MetricKind::GAUGE, value_type: Google::Api::MetricDescriptor::ValueType::INT64, unit: "", labels: [label1] ) metric_client.create_metric_descriptor(formatted_name, md)
type(custom.googleapis.com/custom_metrics_test/test_metric)がこのメトリクスを一意に特定するkeyになります。 metrics_kind, value_typeでメトリクスの種別を定義します。
labelはメトリクスを送信するときに付与することができるラベルの定義です。この場合は"label_test"というkeyに任意の文字列を付与することができます。 MetricDescriptorインスタンスを作ってそれを送信すればokです。
上記をスクリプトを実行すると、StackDriver上にカスタムメトリクスが作成され、Metric Explorerで探して表示することができます。
次は、メトリクスの定義ができたので、そこに書き込んでみます。
metric = Google::Api::Metric.new( type: "custom.googleapis.com/custom_metrics_test/test_metric", labels: {"label_test" => "ラベル付与テスト!!!!"} ) resource = Google::Api::MonitoredResource.new( type: "global", labels: {"project_id" => @project_id} ) point = Google::Monitoring::V3::Point.new( interval: Google::Monitoring::V3::TimeInterval.new( end_time: Google::Gax.time_to_timestamp(Time.now) ), value: Google::Monitoring::V3::TypedValue.new(int64_value: 123456) ) ts = Google::Monitoring::V3::TimeSeries.new( metric: metric, resource: resource, points: [point] ) time_series = [ts] metric_client.create_time_series(formatted_name, time_series)
メトリクスの送信は、TimeSeriesの配列を送信します。TimeSeriesにはMetric, Resource, Pointsという属性があります。
Metricは、送信するメトリクスの定義を指定します。この例では事前に定義した"custom.googleapis.com/custom_metrics_test/test_metric"を指定しています。labelを付与することができます。
Resourceは、監視対象のリソースを指定します。StackDriverで事前に規定されており、global以外にもgce_instance, gee_podなどがあります。このメトリクスを収集したリソースを指定するのがよいと思います。
Pointは、intervalとvalueという属性を含んでいます。valueが記録されるメトリクスの値です。(ここまで長かったですね。。)intervalにはstart_time,end_timeという属性があり、記録するメトリクスのtimestampを指定することができます。メトリクスのtypeでDELTA(差分)を選んだ場合はstart_time, end_time両方の指定が必要になりますが、今回の場合は、end_timeだけでよいです。利用する言語にもよるのですが、Google.ProtoBufで定義されているTimestamp型にする必要があるので注意が必要です。
ここまで成功すれば、StackDriverのコンソールにカスタムメトリクスが表示されることが確認できます。

カスタムメトリクスは有料リソースなのに注意ですが、うまく利用すれば柔軟な監視を構築することができそうです。
Volumeを使わずにDockerコンテナに安全にCredentialを渡す
コンテナ化されたアプリケーションからGCP,AWSなどクラウド上のリソースにアクセスする場合、Credentialを適切な方法でコンテナ内に渡す必要があります。
ほとんどのケースではVolumeMountで大丈夫なのですが、Volumeを使わずに実施する必要があって悩んだのでメモしておきます。
前提
コンテナにCredentialを渡す場合、Dockerfileに記述してしまうのが一番早いのですがそれは好ましくありません。 コンテナ実行時にCredentialを引き渡すのが推奨されている方法のようです。 これはDockerfileに記述してしまうと、Credentialが変わるたびにビルドが必要になってしまうためです。
方法
コンテナ起動時にCredentailを渡す必要があるので、entrypointに処理を挟みます。 Credentialは環境変数にセットすることにしました。
Dockerfile内で
COPY docker-entrypoint.sh /usr/local/bin RUN chmod +x /usr/local/bin/docker-entrypoint.sh ENTRYPOINT ["docker-entrypoint.sh"]
と記述して任意のスクリプトを実行できるようにしておきます。 docker-entrypoint.sh はこれです。
#!/bin/sh set -e if [ -n "$CREDENTIAL" ]; then mkdir /.secrets printf '%s' "$CREDENTIAL" > /. secrets/crendential.json fi exec "$@"
アプリケーションは、CMDに実行するために必要なコマンドを記載し、アプリケーション内で /. secrets/crendential.json を読み込めばokになります。
docker run する場合はこうなります。
CREDENTIAL = `cat path/to/credential.json` export $CREDENTIAL docker run -e CREDENTIAL=$CREDENTIAL image
docker-composeの場合はこんな感じ
- environment: - "CREDENTIAL=${CREDENTIAL}"
APIGatewayパターンとBFF
マイクロサービスアーキテクチャでよく利用される、APIGatewayパターンとBFFについて調べたのでメモ
なぜAPIGateway?
マイクロサービスアーキテクチャでシステムを構築する場合、複数のサービスを組み合わせる形でシステムが構築される。
たとえば、ECサイトの商品詳細を表示するために、商品情報サービス、レコメンデーションサービス、レビューサービスを利用する必要がある、ということ。この場合アプリケーションの実装によっては並行リクエストを行うのが難しかったり、モバイルアプリケーションの場合は帯域の問題も発生する。(その他にもいろいろあるが割愛)
そこで、アプリケーションとサービスの間にAPIGatewayというレイヤーを追加することで問題を解決する。
APIGatewayの実装
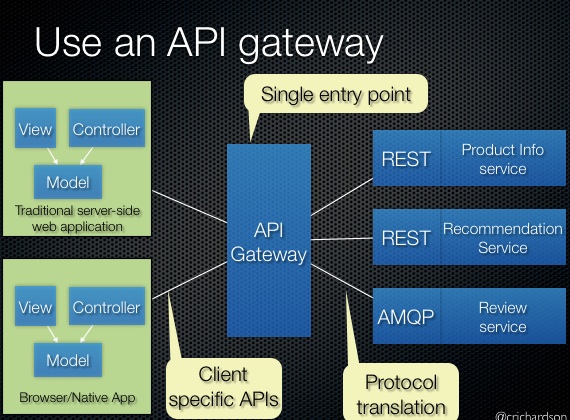 単純な場合はこの図のようになって、全てのアプリケーションからのリクエストを1つのAPIGatewayで受け付ける。
単純な場合はこの図のようになって、全てのアプリケーションからのリクエストを1つのAPIGatewayで受け付ける。
ただ、これはOSFA(one size fit all)APIというアンチパターンになってしまう可能性がある。アンチパターンかどうかは微妙なところだが、Netflixのblog( Embracing the Differences : Inside the Netflix API Redesign - Medium ) でOSAFには限界があるという記述がある。
そこでBFF
アプリケーション毎にAPIGatewayを用意し、それぞれのAPIGatewayは各クライアント専用のエンドポイントを定義する。
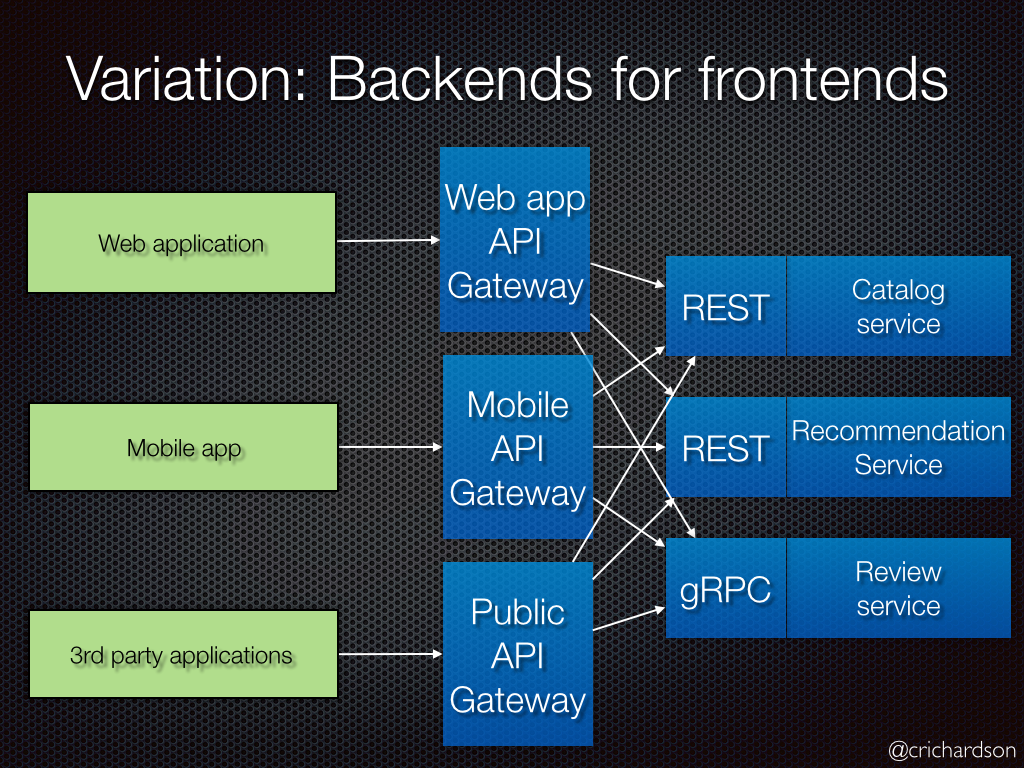
SPAの文脈でNode.jsを置いてそれをBFFと呼んでいることがあるが、マイクロサービスアーキテクチャのBFFとはちょっと違うのかなーという印象。例えばRailsなどのモノシリックのWebアプリケーションを、Node.js + RailsAPIに分割する場合、SPAでいうとNode.jsがBFFになるが、マイクロサービスアーキテクチャのBFFは、Node.jsとRailsAPIの間にAPIGatewayを置くのがBFFになる、はず。(多分
感想
APIGatewayといえばAWSのAPIGateway、BFFといえば、SPAの文脈のサーバサイドJS、というイメージが強く、間違って認識していたことも多かったので改めて調べなおしてよかった。
ソースはここ
Chefで1年運用した感想
仕事でChefを利用しているのですが、なんでこんな難しいんだろうなーという感覚に対して、ある程度自分の答えを出せたのでメモ。
アーキテクチャ
Chefは基本的にClient-Serverモデルです。Cehf Clientをnode(サーバ)にインストールし、Chef Serverからrecipeをダウンロードして実行する、という考え方です。ぱっと思いつく利用方法である「手元でレシピを作ってそれをサーバで実行、適用させる」ことができません。まずnodeとして登録し、そのnodeにroleやrun_listなどの形でレシピを定義し、convergeするという流れになります。
サーバ側は、Nginx, Apache Solr, RabbitMQ, Redisなどなど、かなり分厚い技術スタックを持っています。この辺りがメリットでもありデメリットでもあるんじゃないかなと思います。
Chef Soloはもういない
Chef Soloはもうありません。(といっても4年前の話なのですが。。)
日本語の情報はChef Solo時代で止まってることが多いです。今も流用できる知識は多いのですが、どこまでがChef Solo固有の話なのか判断するのが難しいので基本的にはChef Solo使っていたら読む必要はないと思います。
現在はChef Zeroを利用します。公式のブログがこちら。 blog.chef.io
Chefのメリット
Ansible,Itamaeなどのツールに比べてどういうメリットがあるのかというと、Chef Serverにより、数千台規模までスケールできるアーキテクチャになっていることなんじゃないかなと思います。Chefはこのためにサーバー側をErlangで書き直したようです。 実績として、有名どころではFacebookがあります。
アプリケーションのデプロイについて
Chefでやるかどうかは、利用者の判断に任されている、という認識です。deploy resourceは一応用意されているけど、あまり便利ではありません。ある特定の状態に収束させるという考え方と、頻繁に更新、ロールバックがあるデプロイといは相性が悪いのではと思っています。
正式なサポートとしては、Chef Automateという有料の上位製品で、Chef Workflowというプロダクトがあります。こっちではちゃんとサポートされていそうですが、有料プロダクトなこともあり未検証です。
OpsWorks Stackについて
仕事でChefを触る場合はOpsWorks Stack( https://aws.amazon.com/jp/opsworks/ )の場合が多いんじゃないでしょうか。 OpsWorks Stackは内部的にはChef Zeroを利用していて、cookbook,nodeの管理をOpsWorks Stack独自の方法で行なっています。 そのため、レシピの知識はそのまま流用できますが、Nodeの管理については独自の用語や考え方を学ぶ必要があります(ありました)
また、AWSとしてはあまり積極的にメンテしていく方針ではないみたいで、今後新規で採用するのはちょっと微妙かなと思いました。 今後はChef, Puppetそれぞれの商用製品である、Chef Automate, Puppet Enterpriseをマネージドで提供する方針のようです。OpsWorks Stackとして提供していたソリューションをChef,Puppetそれぞれの商用製品がカバーし始めたため、同じようなツールをAWSとして開発はしない、みたいな感じだと想像してます。
chef-apply
ぱっとレシピを試したい場合は、Vagrantなどで仮想マシンを作ってchef-applyが一番手軽です。 www.creationline.com
最近あまり流行っているように見えない理由
- Ansible, Itamaeの方が手軽
- Docker使い出すとkubernetesという選択肢も。。
- Chefがうまくはまる分野はブログなどでアウトプットすることが少ないエンタープライズ系な気がする
あたりかなと思っています。
まとめ
小規模のシステムにChefを採用するメリットは薄くなってきていると思います。OpsWorks Stackは別でしたが、OpsWorks Stack自体が今後新規で採用するには微妙。
複数のプロダクトを運用している組織全体でChefを利用するのは、Chefが想定しているユースケースにうまくはまりそうな気がしました。今後機会あれば検討してみたいです。
Rubyのマイナーバージョンを上げたらSyntaxErrorになった件
あるプロジェクトのRubyのバージョンを 2.4.0 から2.4.3に上げたら今まで問題なかった構文がSyntaxErrorになるようになりました。経緯が気になって調べたのでそのメモです。
問題の構文は
let :product { create(product)}
のようなものです。(letの括弧を省略して、{}でブロックを渡している)
これが、Ruby 2.4.1までは、
$ruby -ce "m :a {}"
> Syntax OK
となってok 2.4.2(2.4.3と同じ挙動でした)に上げると
$ruby -ce "m :a {}"
>-e:1: syntax error, unexpected '{', expecting end-of-input
m :a {}
^
m(:a {}) と解釈されるみたいでエラー
マイナーバージョンアップで後方互換性壊すことなんてあるのかなーと思ってソースコードを見てみると、それっぽいコミットを発見しました。ちなみに僕は全くRubyのコードは読めません。ただ、構文解析周りだろうなーと思って2.4.1から2.4.2のparse.yに変更があったコミットを調べて見つけました。
このコミットから辿れるruby-coreがこれで
[ruby-core:81037] [Ruby trunk Bug#13547] [].delete 1 { 'NG' }
バグチケットがこれです
Bug #13547: [].delete 1 { 'NG' } - Ruby trunk - Ruby Issue Tracking System
内容を確認すると、2.4.2へのバージョンアップで壊れたのではなく、2.4.0, 2.4.1でだけ意図せず使えていたのがバグで、本来の挙動が文法エラーだったようです。
僕が遭遇した状況と同じようなバグチケットもいくつか確認できました。
Bug #13898: Block parsing regression - Ruby trunk - Ruby Issue Tracking System
Bug #14023: SyntaxError on array argument and block - Ruby trunk - Ruby Issue Tracking System
というわけで、対応としてはRubyはバージョンアップに問題はない。エラーになる構文は今まで通っていたのが間違いだったので全て修正する、ということに。
文法エラーになるようなバグに遭遇したのは初めてだったので、普段何気なく使っているRubyも日々いろんな方の労力で維持・開発されてるんだなーと実感できた出来事でした。 今後はまめにバージョンアップして、何かエラーがあれば報告するぐらいの貢献は行なっていきたい。